This blog post is going to be a tutorial on how to fine-tune a LLM with LoRA and the mlx-lm package. Medium post can be found here and Substack here.
Introduction
MLX is an array framework tailored for efficient machine learning research on Apple silicon. Its biggest strength is that it leverages the unified memory architecture of Apple devices and offers a familiar, NumPy-like API. Apple has also developed a package for LLM text generation, fine-tuning, etc. called MLX LM.
Overall, mlx-lm supports many of Hugging Face format LLMs. With mlx-lm it is also very easy to directly load models from the Hugging Face MLX Community. This is a place for mlx model pre-converted weights that run on Apple Silicon, hosting many ready-to-use models with the framework. The framework also supports parameter-efficient fine-tuning (PEFT) with LoRA and QLoRA. You can find more information about LoRA in the following paper.
In this tutorial, with the help of the mlx-lm package, we are going to load the Mistral-7B-Instruct-v0.3–4bit model from the MLX Community space, and attempt to fine-tune it with LoRA and the dataset win-wang/Machine_Learning_QA_Collection. Let's begin.
Packages and Model Loading
First, we have to load the needed packages.
import json
import os
from typing import Dict, List, Optional, Tuple, Union
import matplotlib.pyplot as plt
import mlx.optimizers as optim
from mlx.utils import tree_flatten
from mlx_lm import generate, load
from mlx_lm.tuner import TrainingArgs, datasets, linear_to_lora_layers, train
from transformers import PreTrainedTokenizer
Then, we should load the model and tokenizer.
model_path = "mlx-community/Mistral-7B-Instruct-v0.3-4bit"
model, tokenizer = load(model_path)
Let's see what would our model output when given a simple pormpt such as "What is fine-tuning in machine learning?".
prompt = "What is fine-tuning in machine learning?"
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
The generated output of the model is:
Fine-tuning in machine learning refers to the process of taking a pre-trained model, which has already been trained on a large dataset for a specific task, and adapting it to a new, related task or a different aspect of the same task.
For example, imagine you have a pre-trained model that can recognize different types of animals. You can fine-tune this model to recognize specific breeds of dogs, or even to recognize different types of flowers. The idea is that the pre-trained model has already learned some general features that are useful for the new task, and fine-tuning helps the model to learn the specific details that are important for the new task.
Fine-tuning is often used when you have a small dataset for the new task, as it allows you to leverage the knowledge the model has already gained from the large pre-training dataset. It's a common technique in deep learning, particularly for tasks like image classification, natural language processing, and speech recognition.
Preparation for Fine-Tuning
Let's create an adapters directory, and the paths to the adapter configuration (in our case the LoRA configuration) and adapter files.
adapter_path = "adapters"
os.makedirs(adapter_path, exist_ok=True)
adapter_config_path = os.path.join(adapter_path, "adapter_config.json")
adapter_file_path = os.path.join(adapter_path, "adapters.safetensors")
We have to set our LoRA parameter configurations. This can be done in a separate .yml file, as shown here, but for code simplicity and the sake of just showing the process of fine-tuning with LoRA and mlx-lm, we are going to stick to this simple in-code configuration
lora_config = {
"num_layers": 8,
"lora_parameters": {
"rank": 8,
"scale": 20.0,
"dropout": 0.0,
},
}
which we save into the adapters directory we already created.
with open(adapter_config_path, "w") as f:
json.dump(lora_config, f, indent=4)
We can also set our training arguments, pointing to our adapter file, how many iterations we want to perform, and how many steps per evaluation should be done.
training_args = TrainingArgs(
adapter_file=adapter_file_path,
iters=200,
steps_per_eval=50,
)
In the LoRA framework, most of the model's original parameters remain unchanged during fine-tuning. The model.freeze() command is used to set these parameters to a non-trainable state so that their weights aren't updated during backpropagation. This way, only the newly introduced low-rank adaptation matrices (LoRA parameters) are optimized, reducing computational overhead and memory usage while preserving the original model's knowledge.
The linear_to_lora_layers function converts or wraps some of the model's linear layers into LoRA layers. Essentially, it replaces (or augments) selected linear layers with their LoRA counterparts, which include the additional low-rank matrices that will be trained. The configuration parameters (like the number of layers and specific LoRA parameters) determine which layers are modified and how the LoRA adapters are set up.
We should also verify that only a small subset of parameters are set for training, and activate training mode while preserving the frozen state of the main model parameters.
model.freeze()
linear_to_lora_layers(model, lora_config["num_layers"], lora_config["lora_parameters"])
num_train_params = sum(v.size for _, v in tree_flatten(model.trainable_parameters()))
print(f"Number of trainable parameters: {num_train_params}")
model.train()
We can also create a class to follow the train and validation loss metrics during the training process
class Metrics:
def __init__(self) -> None:
self.train_losses: List[Tuple[int, float]] = []
self.val_losses: List[Tuple[int, float]] = []
def on_train_loss_report(self, info: Dict[str, Union[float, int]]) -> None:
self.train_losses.append((info["iteration"], info["train_loss"]))
def on_val_loss_report(self, info: Dict[str, Union[float, int]]) -> None:
self.val_losses.append((info["iteration"], info["val_loss"]))
and create an instance of this class.
metrics = Metrics()
Data Loading
Here, we are creating a simplified variant of the following function for loading a Hugging Face dataset.
def custom_load_hf_dataset(
data_id: str,
tokenizer: PreTrainedTokenizer,
names: Tuple[str, str, str] = ("train", "valid", "test"),
):
from datasets import exceptions, load_dataset
try:
dataset = load_dataset(data_id)
train, valid, test = [
(
datasets.create_dataset(dataset[n], tokenizer)
if n in dataset.keys()
else []
)
for n in names
]
except exceptions.DatasetNotFoundError:
raise ValueError(f"Not found Hugging Face dataset: {data_id} .")
return train, valid, test
Then, let's load the win-wang/Machine_Learning_QA_Collection dataset from Hugging Face.
train_set, val_set, test_set = custom_load_hf_dataset(
data_id="win-wang/Machine_Learning_QA_Collection",
tokenizer=tokenizer,
names=("train", "validation", "test"),
)
Fine-Tuning
Finally, we can begin the LoRA fine-tuning process by calling the train() function.
train(
model=model,
tokenizer=tokenizer,
args=training_args,
optimizer=optim.Adam(learning_rate=1e-5),
train_dataset=train_set,
val_dataset=val_set,
training_callback=metrics,
)
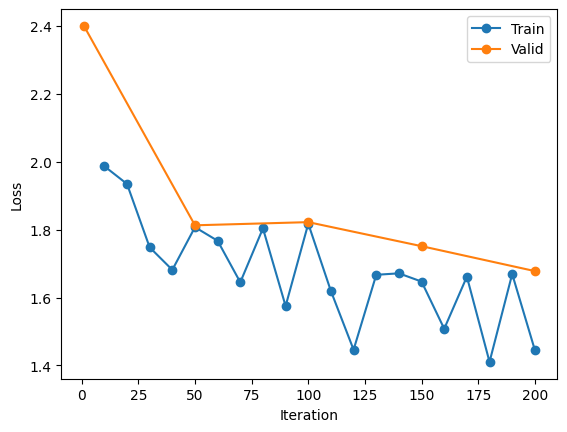
After the training is completed, we can also plot the train and validation loss.
train_its, train_losses = zip(*metrics.train_losses)
validation_its, validation_losses = zip(*metrics.val_losses)
plt.plot(train_its, train_losses, "-o", label="Train")
plt.plot(validation_its, validation_losses, "-o", label="Validation")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.legend()
plt.show()
For example, one of the trainings performed resulted in the following losses.
Test the model_lora
Now, we can load the fine-tuned model, specifying the adapter_path,
model_lora, _ = load(model_path, adapter_path=adapter_path)
and we can generate an output for the same prompt as earlier.
response = generate(model_lora, tokenizer, prompt=prompt, verbose=True)
The generated response is:
Fine-tuning in machine learning refers to the process of adjusting the parameters of a pre-trained model to adapt it to a specific task or dataset. This approach is often used when the available data is limited, as it allows the model to leverage the knowledge it has already gained from previous training. Fine-tuning can improve the performance of a model on a new task, making it a valuable technique in many machine learning applications.
Conclusion
In this tutorial, we explored how to leverage MLX LM and LoRA for fine-tuning large language models on Apple silicon. We started by setting up the necessary environment, loading a pre-trained model from the MLX Community, and preparing our dataset from Hugging Face. By converting selected linear layers into LoRA adapters and freezing the majority of the model's weights, we efficiently fine-tuned the model using a modest computational footprint. This approach not only optimizes resource usage but also opens the door to experimenting with different fine-tuning strategies and datasets. Further modifications can be explored, such as experimenting with other adapter configurations like QLoRA (extends the LoRA approach by integrating quantization techniques), fusing adapters, integrating additional evaluation metrics to better understand a model's performance, etc. Happy fine-tuning!