"When we ask a language model a question, we often leave out important context. A query like, "Is coffee good for you?" seems straightforward, but a quality response depends on hidden context about the user (e.g., does the user have high blood pressure? Are they pregnant?)."
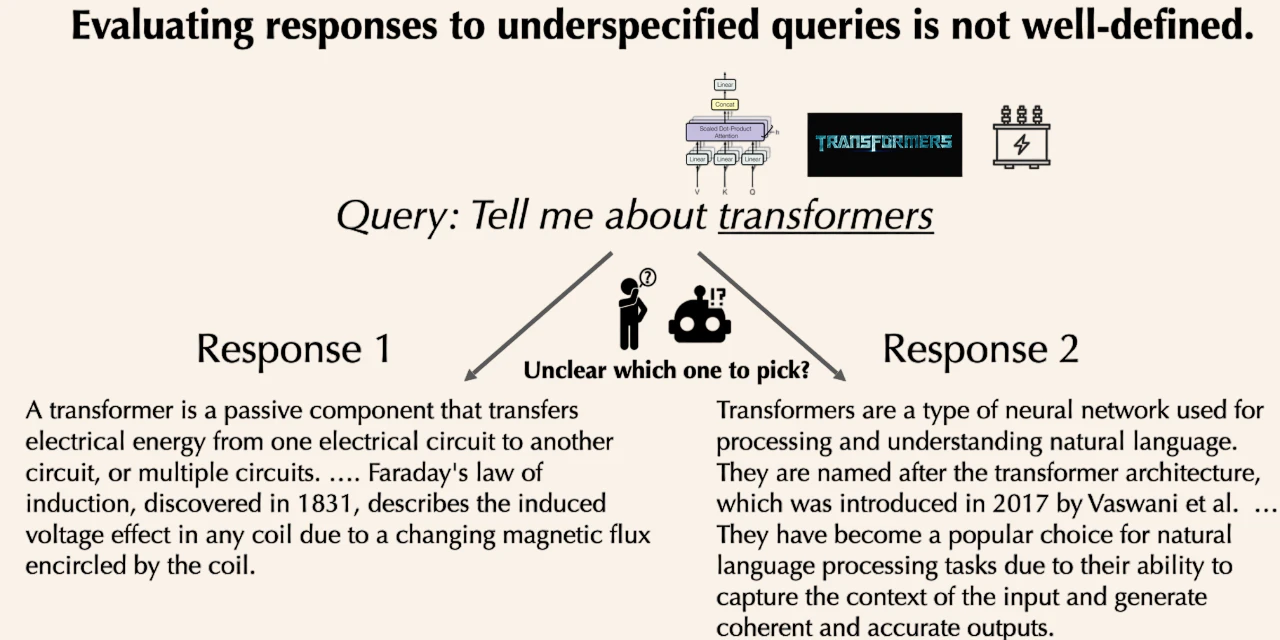
New research from Ai2, "Contextualized Evaluations: Judging Language Model Responses to Underspecified Queries", reveals a major flaw in how we benchmark language models. When we ask vague questions like "Is coffee good for you?" or "Tell me about transformers", we're missing crucial context that determines what makes a good response.
The problem:
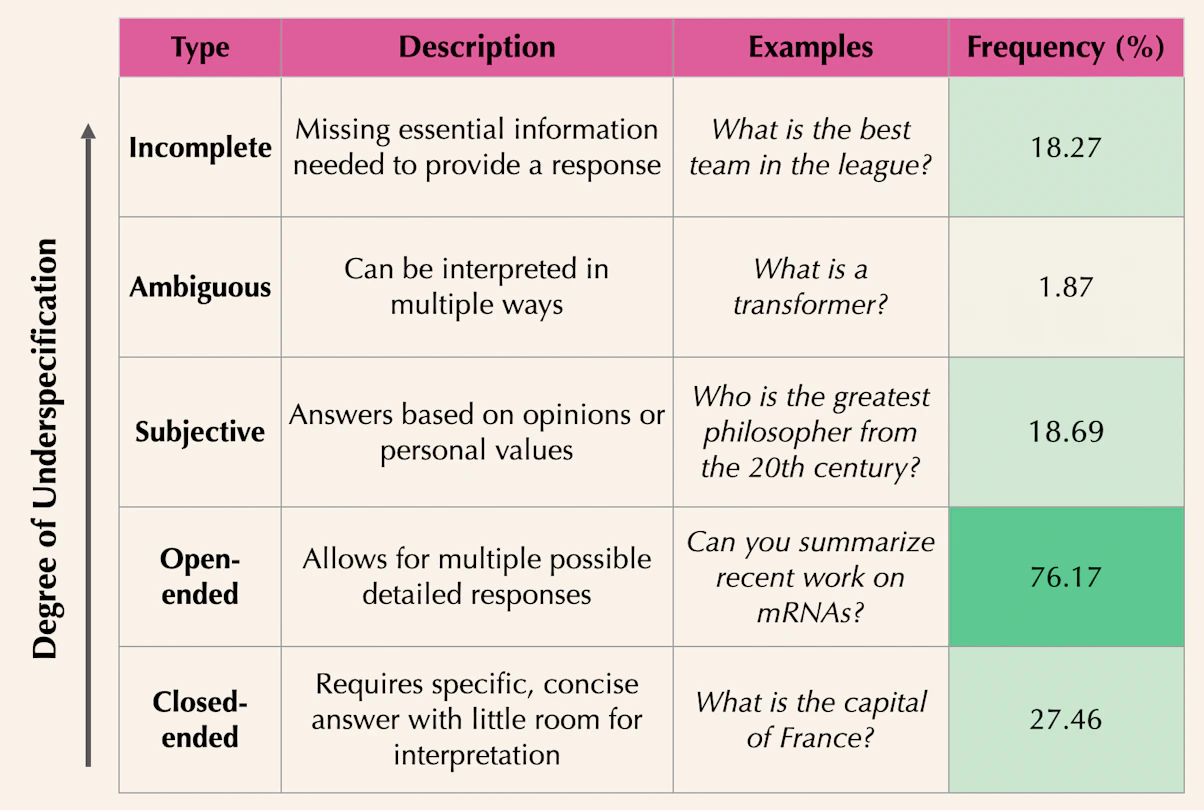
\(\sim 76\%\) of queries in major AI benchmarks are underspecified, leading to inconsistent evaluations and unreliable model rankings.
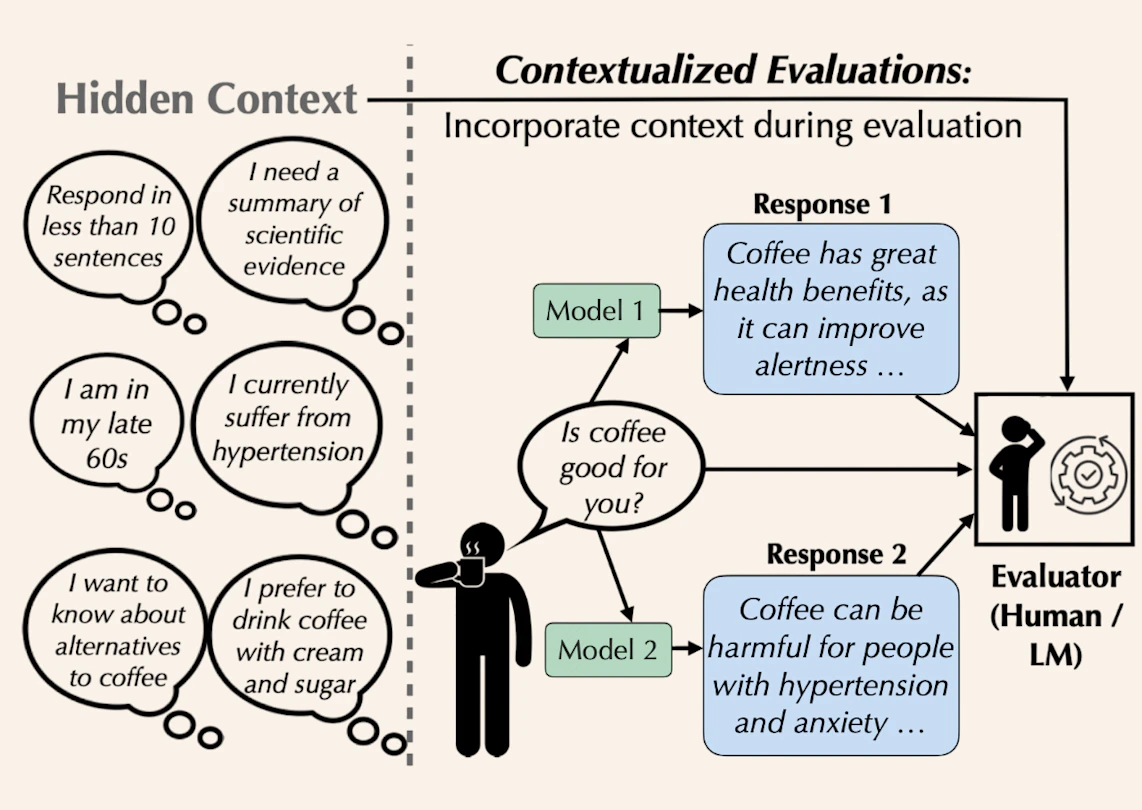
The solution:
"Contextualized Evaluations" – adding synthetic context through follow‑up questions before evaluation. For example, that coffee question needs to know: Are you pregnant? Do you have high blood pressure?
Key findings:
✅ Context improves evaluator agreement by 3–10%
✅ Can completely flip model rankings
✅ Shifts focus from style to actual usefulness
✅ Reveals models have a "WEIRD bias" – defaulting to responses for Western, educated, wealthy users
Why this matters:
Current AI leaderboards might not reflect how well models actually serve diverse users or adapt to specific needs. This research offers a simple way to make AI evaluations more reliable and inclusive.
Read more:
📬 Blog post: https://allenai.org/blog/contextualized-evaluations
🗒️ Paper: https://arxiv.org/abs/2411.07237